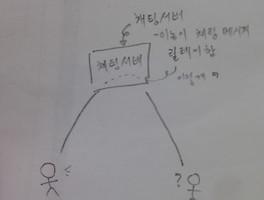
오래간만에 휴가 기간이다. 아무런 생각도 하지말고 '분산 시스템'이라는 주제에 대해 포스팅을 시작해 보자.
분산 시스템(Distributed System)?
분산 시스템의 교과서 적인 Distributed System Concepts (Andrew S. Tanenbaum) 의 말을 빌리자면 "하나의 시스템 처럼 보이는 독립된 컴퓨터들의 집합"(A distributed system is a collection of independent computers that appears to its users as a single coherent system)이라고 정의하고 있다.
하나의 시스템 처럼 보이는 독립된 컴퓨터들의 집합
위의 정의를 두 가지 주요한 관점으로 바라 볼 수 있다. 한가지는 하드웨어 - 독립되어 자율적으로 돌아가는 하드웨어 머신, 다른 한 가지는 소프트웨어 - 유저 관점에서 보았을 때 마치 하나의 시스템으로 여겨지는 시스템. 위 두가지 사항은 분산 시스템을 구성하는 핵심적인 요소이며 시스템을 디자인 할 때 절대 잊어서는 안되는 원칙이다.
위 두 가지 대 원칙을 가지고 분산 시스템을 디자인 할 때, 다시 아래의 생각들을 해봐야 한다.
- 다양한 컴퓨터(or 장비)들 사이에 다양한 통신 방법들을 어떻게 사용자로 부터 숨길 것인가?
- 어떻게 사용자와 시스템 간의 일관적이고 단일화된 커뮤니케이션 통로만들 것인가?
지금 까지 컴퓨터 네트워크의 발전사를 살펴 보면 다양한 커뮤니케이션 방법, 컴퓨터의 종류, 통신 장비들을 이용하기 위해서 레이어(Layer)를 두고 각 레이어마다 프로토콜을 정해 사용자에겐 자신이 직접적으로 닿고 있는 레이어만 신경쓰면 얼마든지 시스템에 접근 할 수 있도록 하는 형태로 발전해 왔다. 예를 들자면 OSI 7 layer, TCP/IP 와 같은 것들이 있다.
위와 같은 레이어링은 하드웨어 뿐만 아니라 소프트웨어 디자인에도 상당한 도움이 된다는 사실을 기억하자.
분산 시스템의 목적?
그렇다면 왜 유저 관점에서 하나 처럼 보이지만 뒤에서는 여러 다양한 컴퓨터들로 구성되어 있는 복잡 다단한 분산시스템이라는 것을 만들어야 하는 것일까?
내가 생각하는 가장 첫번째 이유는 자원의 부족 때문이다. 여기서 말하는 '자원'이라는 것에는 컴퓨터의 CPU 파워, 메모리, 하드 디스크 스토리지 등등 우리가 사용하는 모든 컴퓨터의 자원을 의미한다. 요즘 같은 서버-클라이언트 구조의 서비스들이 점점 더 발달할 수록 더 많은 자원을 요구하게 되고, 머신 한 대로 처리 할 수 있는 양에는 한계가 있다. 그래서 우리는 분산 시스템을 도입하여 위의 문제를 해결한다.
두 번째는, 장애시 대처다. 단일 머신에서 돌아가는 시스템이라면 해당 머신의 수명이 다하거나 어떠한 불의의 사고로 다운이 되게 된다면 모든 시스템이 다운되게 된다. 하지만 여러 대의 머신이 분산하여 연산을 처리하고 데이터를 저장하고 있다면 한대의 장애가 전체 시스템의 장애로 이어지지는 않는다. 이를 위해서도 분산 시스템은 필요하다.
셋 째, 사용자에게 자원 접근의 편리성을 제공하기 위해서다. 사용자는 많은 종류의 다양한 자원들에 접근을 요구한다. 이때 사용자에게 일관적이고 단일화된 방식으로 사용자가 원하는 자원에 쉽게 접근하게 할 수 있는 것이 바로 분산 시스템이다. 예를 들어서 특정 인터넷 페이지가 있다고 가정해 보자. 우리는 이 페이지를 저장하고 있는 서버가 어디에 있으며 아이피가 무엇인지 알지 못한다. 하지만 인터넷 브라우저에 url을 입력하면 우리가 원하는 사이트에 접속하고, 우리가 원하는 정보를 얻을 수 있다. 여기서 url은 단일화된 자원 접근 방법이고, 앞에서도 말했다 싶이 사용자는 이 자원이 실제 세계 어떤 서버에 있는지에 대한 고민은 전혀 하지 않아도 된다.
위와 같은 특성들을 통틀어 투명성(Transparency)이라고 한다. 사용자는 어디에 어떤 자원이 어떻게 저장되어 있는지 알필요 없고, 몇 대의 시스템이 어떻게 구성되어 돌아가는지 알 필요가 없다. 이런 투명성은 아래와 같이 여덟가지 항목에 적용해 볼수 있다.
- Access : 데이터 표현 방식, 자원에 접근 방법을 사용자에게 숨긴다.
- Location : 자원이 어디에 위치하고 있는지 사용자에게 숨긴다.
- Migration : 자원의 이동을 사용자에게 숨긴다(이동하더라도 동일한 방법으로 접근 할 수 있음을 의미한다)
- Relocation : 사용자가 사용 중임에도 자원이 이동 할 수 있다. 하지만 이 사실을 사용자에게 숨긴다.
- Replication : 자원은 복사 될 수 있다. 하지만 사용자는 자기가 복사본에 접근하는지, 원본에 접근하는지 모른다.
- Concurrency : 접근 자원이 다른 사용자와 함께 공유되고 있어도 사용자는 모른다.
- Persistance : 자원이 메모리에 있든, 하드디스크에 있든 사용자는 모른다.
위와 같은 투명성을 제공하여 머신 자원 부족과 장애 대처, 사용자에게 자원에 대한 접근 편리성을 제공하는 것이 분산 시스템의 목적이라고 할 수 있겠다...라고 책을 보고 나름 생각한 것을 주장한 것이라 꼭 이게 맞다고는 말 못하겠다...;;